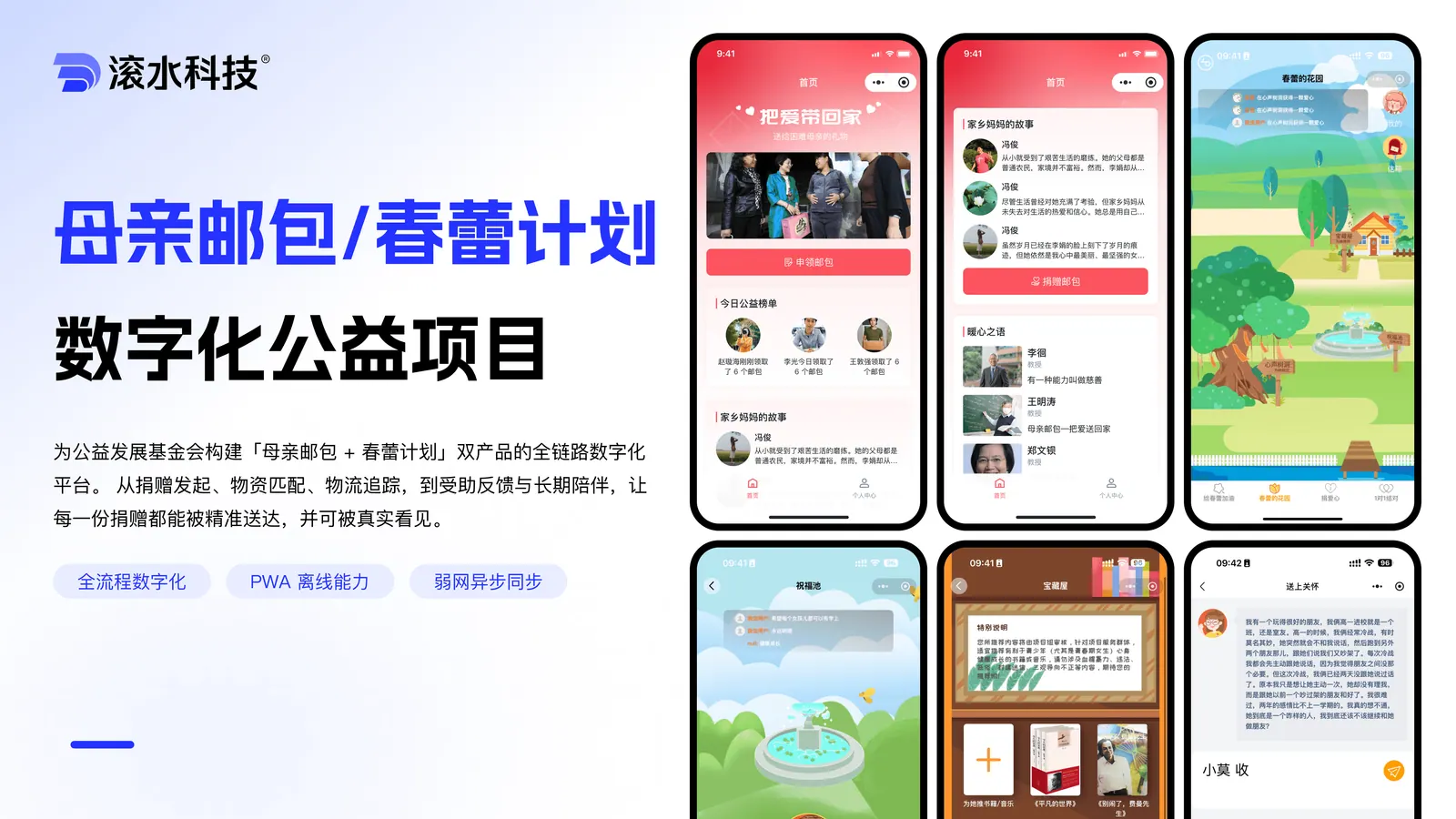
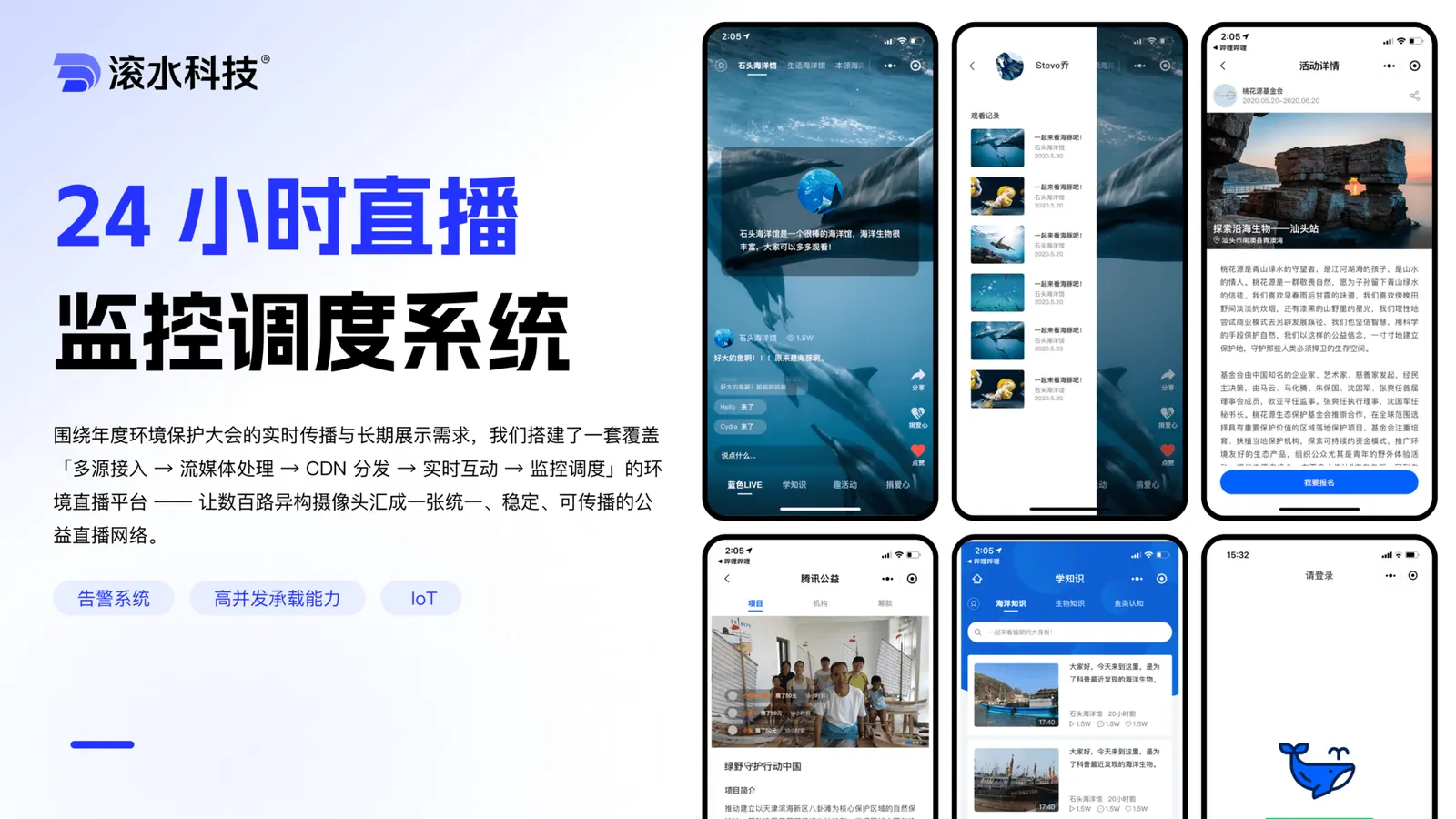
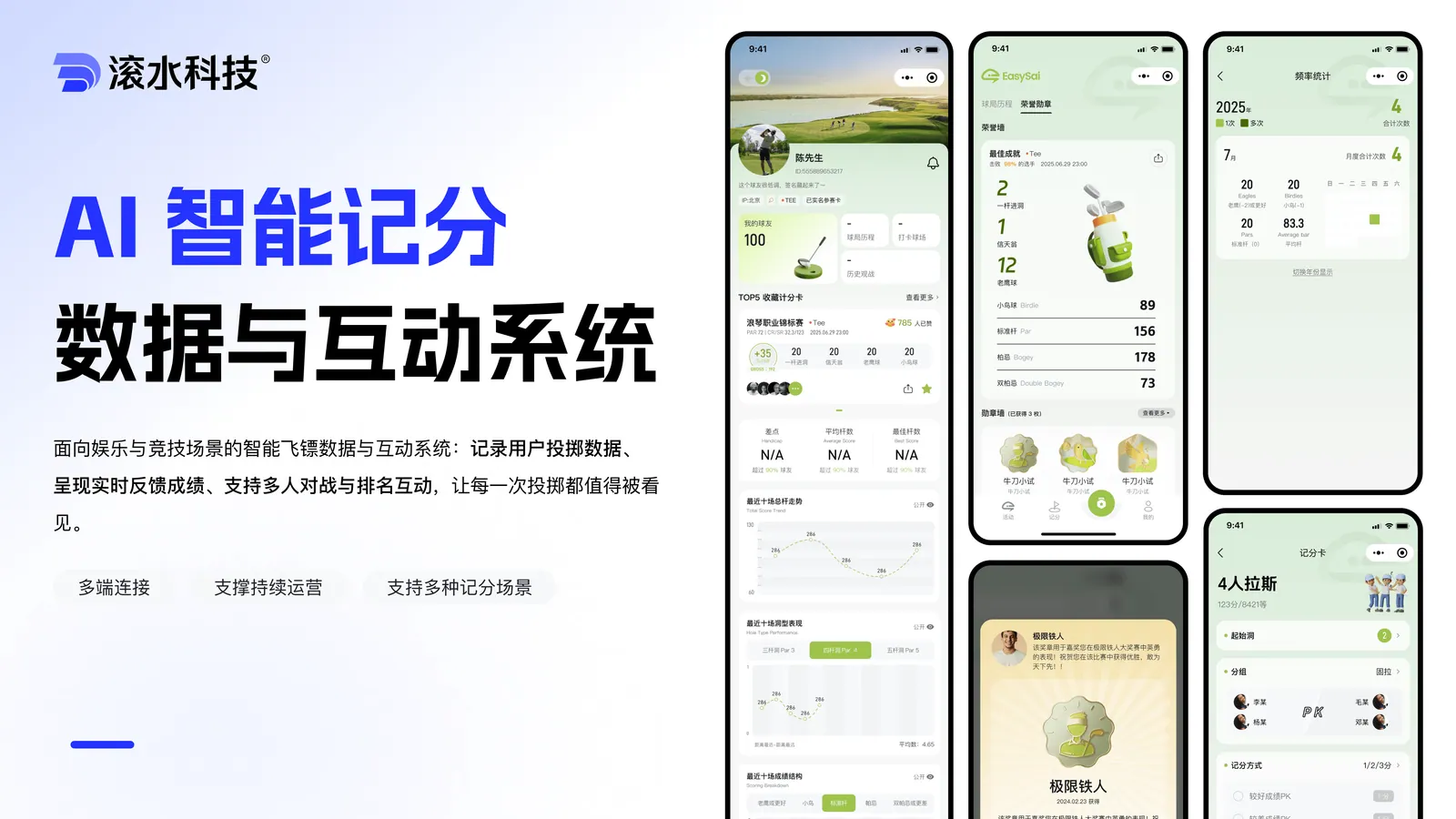
P-01
不同 HR,筛出来的人完全不一样
同一个岗位:A HR 看学历、B HR 看大厂背景、C HR 看关键词数量。最后进入面试的人差异非常大。
客户内部第一次意识到:招聘标准并没有被真正结构化。
2025 年底,这家拥有多条业务线的集团客户同时开启新一轮技术岗扩招。最开始的解法很朴素:加人。但很快他们发现 —— 人数增加,并没有解决问题。
而是把大量时间,消耗在"整理简历"这件事上。真正进入筛选环节时,新的问题才开始浮现。
JD 里写着「高并发 / 微服务 / 分布式缓存」,候选人却写着「秒杀系统 / Spring Cloud 重构 / Redis 热点」。对技术团队是同一类能力,对非技术 HR 而言,几乎无法在几十秒内做出判断。
同一个岗位:A HR 看学历、B HR 看大厂背景、C HR 看关键词数量。最后进入面试的人差异非常大。
客户内部第一次意识到:招聘标准并没有被真正结构化。
搜 "Go 开发",写 "Golang / 云原生后端 / 微服务开发" 的人根本不会被召回;搜 "用户增长",写 "Growth / 增长运营 / 裂变策略" 的简历也大量漏掉。
ATS 能找到「写得像 JD 的人」,但找不到「真正合适的人」。
业务团队频繁反馈"很多不错的人根本没进来";技术主管不得不重新参与第一轮筛选 —— HR 效率下降、技术团队被迫重复劳动、招聘周期继续拉长。
最严重时,一个 Java 岗位首次查看等待 > 72 小时。
纯大模型方案在真实生产环境中很快暴露出三个明显问题。这一次工程判断,决定了整个项目后续的方向。
同一份简历,不同时间、不同 Prompt,评分会出现明显波动。HR 没办法建立信任 —— 信任成本,是 AI 工具上线的第一道门槛。
HR 最常问的不是「为什么是 82 分」,而是「为什么他比另一个人高」。无法解释技能来源、经验关联、岗位依据,HR 最终还是会人工再筛一遍。
十万级简历库下,全部走完整大模型推理 —— 延迟、Token 成本、并发稳定性都会成为问题。AI 反而变成新的负担。
让不同模块分别做自己最擅长的事:规则负责稳定、向量召回负责覆盖、LLM 负责理解上下文。 AI 不再"一票否决",而是作为评分体系的一部分参与决策。
工程化 ≠ 调用大模型。我们把整套招聘流程重新拆解,让每个模块只做它最擅长的事,让 AI 真正可控、可解释、可信任。
这是最容易被忽略的部分。第一步不是 AI,而是 RPA + OCR + 格式归一:从多平台抓取、自动去重、识别 PDF / Word / 图片,进入同一套标准数据结构。
当 JD 写"高并发经验",系统会同时理解 Redis / Kafka / 秒杀系统 / 分布式缓存 / 服务治理 之间的上下文关系。匹配的不是「词」,而是「这个人有没有真正做过类似事情」。
最初我们让模型直接输出分数,但波动大、不稳定、难解释。最终改成「规则主导 + AI 辅助」:技能 / 经验 / 语境深度 / 逻辑结构 / 岗位契合 五维加权,AI 负责理解上下文,而不是拍板。
候选人写"做过高并发优化",传统 HR 很难继续追问。系统基于项目经历、技术栈、岗位要求自动生成「缓存击穿怎么处理?」「Kafka 分区为什么这么设计?」这种继续往下挖的问题。
客户后来评价:"以前技术主管要帮 HR 一起做初筛,现在终于能拆开了。"
我们把一份真实简历(脱敏后)完整跑了一遍:3 页 PDF、格式混乱、口语化表达 —— 整个过程小于 10 秒。
提取技能、项目、时间线、教育背景、工作轨迹。
识别 "Redis + Kafka 优化" 对应分布式缓存 / 消息队列 / 高并发治理,并与岗位需求做向量匹配。
技能 / 经验 / 语境深度 / 逻辑结构 / 岗位契合 加权后形成雷达图。
技术追问 + 项目追问 + 架构问题 + 风险问题,直接交给面试官。
Java 后端 · 5 年 · 分布式经验匹配
从简历入库、人才库管理,到智能搜索、深度分析、面试题生成 —— 完整的五个关键界面,对应案例正文中的五条主链路。

Outlook / Gmail / 网易邮箱 / QQ 邮箱 / 企业微信 等 5 类来源一键打通,RPA 持续监听新邮件、自动解析附件、统一字段,再进入下游处理 —— 这是「简历收不上来」问题真正被解决的入口。
这些问题,比「调用大模型」复杂得多。它们决定了一套 AI 系统能不能真正跑在生产环境里。
整个招聘流程,第一次真正形成「人机协同」。
把"看完第一轮世界"这件事交给系统 —— 让规则负责稳定,让模型负责理解,让评分可以解释。
HR 回到她们最该做的工作 —— 与人对话、判断契合、推进沟通、识别风险。这是 AI 替代不了的部分。
「招聘不是筛关键词,
而是在理解人。」
所以最后真正有效的,不是「AI 替代 HR」。 而是 ——「AI 先帮 HR 看完第一轮世界。」
解决 HR 在大量简历筛选、岗位 JD 编写、初轮电话沟通中的重复性劳动,让 HR 聚焦终面与人才发展。核心模块包括 JD 智能生成、简历语义匹配、AI 电话初筛与候选人画像。
是 AI 语音 + 大模型对话,平均通话时长 5–8 分钟。开场会主动告知"本次电话由 AI 助理发起",并提供随时转人工的入口,符合《个人信息保护法》对自动化决策的告知义务。
目前支持 BOSS 直聘、智联招聘、拉勾、LinkedIn 等主流招聘渠道的简历同步,并提供与 Moka、北森、HR 等 ATS 的标准 OpenAPI 对接。也可针对客户自研 ATS 提供 SDK 适配。
在试点客户(5,000+ 岗位 / 30 万+ 简历的样本)上,AI 给出 Top 10 候选简历与 HR 最终面试通过简历的重合率约 78%。匹配模型支持基于客户历史录用数据持续 fine-tune。
SaaS 版可在 2 周内开通试点;定制版(含 JD 模板定制 + 私有化部署)通常 6–10 周。计费模式分两档:按岗位订阅(年)或按通话分钟数(适合季节性招聘高峰)。
我们做过 1,500+ 候选人匿名调研:78% 觉得 AI 初筛"比传统短信问卷更友好",理由是节奏可控、可随时打断、不会问敏感隐私问题。所有通话录音明示告知并提供候选人查看入口。
Related cases
更多由滚水科技交付的项目案例,覆盖 AI、IoT、平台型业务与企业管理。
这类案例通常涉及业务系统、设备接入、AI 工作流或多角色后台。我们会按真实交付链路评估可行性,并给出更接近实施阶段的建议。